
Author: Emil Kutanov
Engineers are constantly on the lookout for ways of doing more with less. This post a gentle reminder that less, contrary to the cliché, is not always more.
I am cheerfully reminded of an old Top Gear episode, in which the protagonists get £10,000 each to buy a used, mid-engined Italian supercar for a drive from Bristol to a Gentleman’s club in Slough. In a classical Top Gear fashion, carnage ensues: Hammond goes for a rust bucket Ferrari 308 GT4, Clarkson buys an “unstoppable” Maserati Merak (with brakes that had seen better days), and May brings in a Lamborghini Urraco that is broken down right from the start (arriving on the back of a truck, owing to temperamental electrics). The episode really delivers — from an entertainment point of view. The cars themselves were genuinely awful; none making it through to the end of filming.
You may think, he’s getting off his rails. What does all this have to do with databases and Kafka? Well, for starters, the episode was aired in 2011, which is the same year that Kafka was released by LinkedIn. But I promise you, it’s not that.
What’s prompted all this? Well, the Interweb is full of peculiar comparisons and outlandish pseudo-logical implications. For example, because Apache Kafka is a piece of persistent middleware, some Internet “experts” are keen to point out that it is, in fact, a database! It lets you store records and retrieve them, surely that’s a database. No, it isn’t, but that’s somewhat beside the point. My interest has recently been piqued by a rarer, even more extraordinary assertion — a reciprocal of the former, if you like. Namely, that due to their alleged likeness, you don’t actually need Kafka — all you need is a plain old database. Messaging: solved! Ostensibly.
Taking a moment to clarify, I have been inundated with suggestions about the prospect of emulating key parts of Kafka, sans the broker. Why adopt the world’s most popular open-source event streaming platform when you can build your own with a quick trip to the parts bin. All you need is a database and a little programming elbow grease?
I recently did a short piece on Quora, explaining succinctly why this is such a terrible idea. Here, I have the opportunity to elaborate.
To be fair, the crux of that particular Quora question wasn’t substituting Kafka with a like-for-like database-backed solution, with all the bells and whistles, but more likely a quick-and-dirty way of achieving rudimentary persistent messaging capability on the cheap without committing to a full-blown messaging platform — another set of cogs with their own deployment and maintenance overheads, infrastructure requirements, technical learning curves and all that jazz. And on the face of it, it’s a solid argument — why consciously introduce complexity when a comparable outcome may be achieved with a lot less? So, let’s dig deeper.
We’ve all been there: asked to achieve immensely ambitious targets in aggressive time frames by an organisation that seemingly cares little about building sustainable software-intensive systems that add value over the long term. Perhaps you’re treading sweat equity in a startup, or working for a large merchant bank… And to top it off, your team lead or friendly development manager has committed you to a task that requires drastic engineering compromises to meet its objectives. Rather than using the correct tool for the job, the team decides to make do with what’s at hand. After all, time is of the essence. Those managerial bonuses aren’t going to earn themselves. (Actually, you’d be surprised.)
The overarching premise is simple. Take a shared database server — either a relational model or a document store. Write events as records into a table (or bucket, collection, index, whatever) from a producer process. (The exact terminology depends on the database in question; so, we use the term ‘table’ in the broadest, most generalised sense.) The database might use one table to persist all event records, with an indexed attribute to denote the event type — emulating the notion of a ‘topic’. Furthermore, topics may further be decomposed by ‘partition’, using another indexed attribute capture record keys or their hashes. Conveniently, the use of a sharded No/NewSQL database can aid scalability, as topics and partitions can be spread across an active-active cluster of database nodes.
Periodically poll the database from a consumer instance, updating the state of the consumer upon processing the record. Where the database supports this, use a continuous query on the consumer-side to minimise both the resource overhead and the latency of periodic querying. (Continuous querying is becoming more commonplace in NewSQL products; although it is still somewhat rare in mainstream SQL databases.) Ideally, the model should allow for multiple producers and consumers to operate concurrently; otherwise, the scalability of the system will be compromised. Failing to support concurrent consumers, the system should at least support active-passive failover; otherwise, availability will suffer as a result.
The diagram below illustrates a conceptual model of our makeshift event bus.
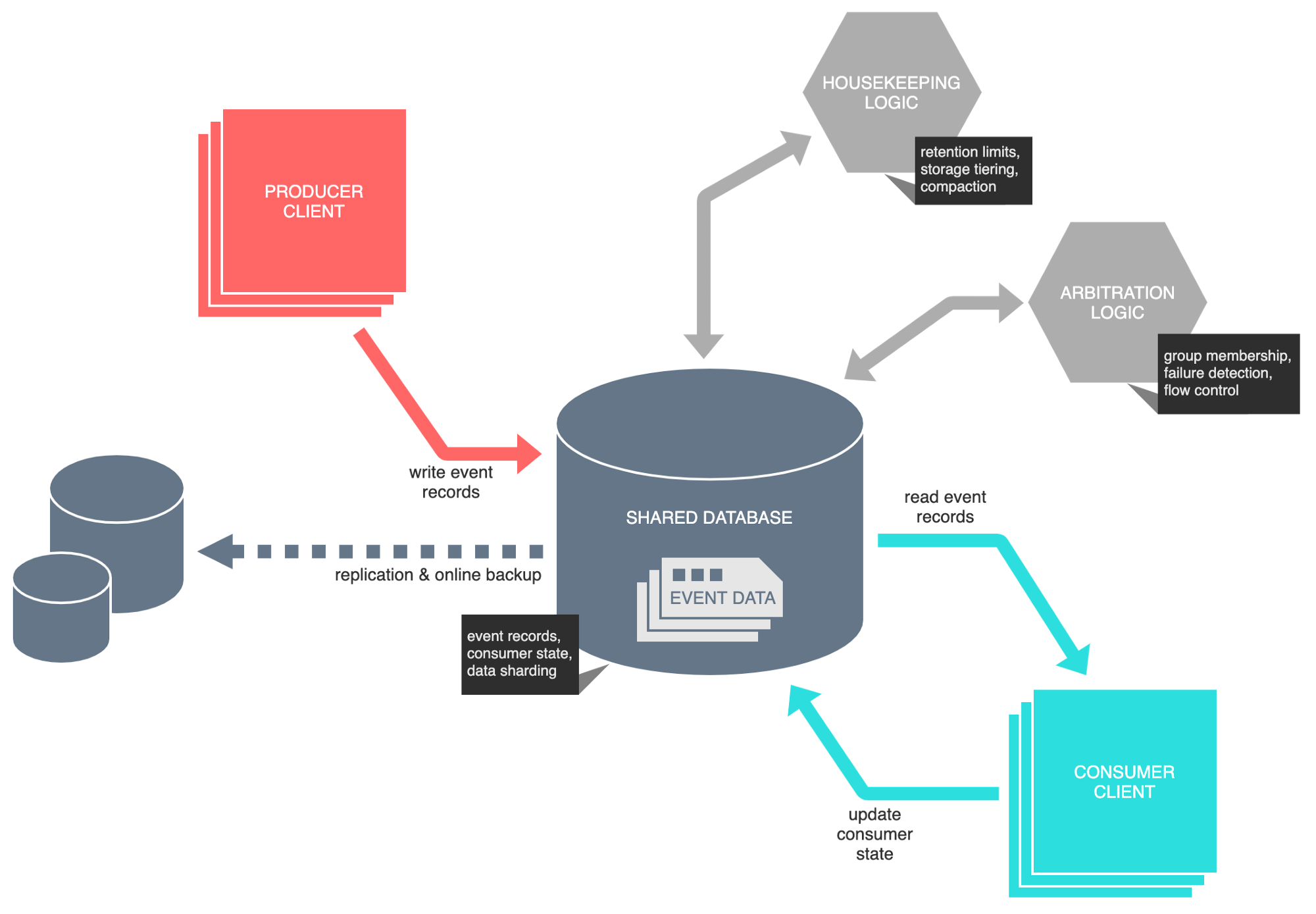
Artist’s impression of a database-backed event bus [Image by author]
The precise mechanism for tracking consumer state and dealing with disjoint groups of consumers is unspecified. You might consider taking a leaf from Kafka’s book and employ offsets to track consumer location, while persisting records beyond their logical consumption — thereby supporting multiple sets of consumers out of a single persistent data set. Alternatively, disjoint consumer groups might be implemented by duplicating records at the point of insertion, deleting records post-consumption.
There are a few more items in the diagram worth noting. The first is labelled ‘arbitration logic’. We need a mechanism to arbitrate the consumption of record data, such that no record is consumed simultaneously by two related consumers and that records are processed in the correct order — the safety property of our system. Furthermore, we need to ensure that the occasional failure of consumers does not impede progress — the liveness property. Both properties are crucial in the design of distributed systems.
Another important item on our diagram is labelled ‘housekeeping logic’. This relates to the need to purge stale data, ensuring we don’t get carried away and run out of storage. Alternatively, we may move older data to a cheaper storage tier, rather than purging it irrevocably. Housekeeping may also include activities such as record compaction — dropping events that have been superseded by more recent event ones, avoiding extraneous processing downstream.
With the architectural pieces in place, let’s see how the game plays out.
From a functional standpoint, it is certainly possible to devise a messaging system on top of a database. However, you will soon realise that a database will only supply you with the bare-essential persistence needs — the storage and retrieval of records, backup and replication (illustrated above), as well as (in some products) high availability and/or horizontal I/O scaling. You might even get atomic transactions.
Platforms like Kafka are concerned with streaming record-centric data, which mainly involves the distribution — not just the persistence of records. This is where it gets tricky. In building a distribution layer, you will almost invariably end up reinventing the wheel when it comes to emulating even a subset of the essential capabilities that Kafka offers out of the box.
For example, Kafka has built-in mechanisms for fanning out data and supporting multiple disjoint consumers by way of persistent offsets, which are managed automatically via a construct called a consumer group. Kafka also allows you to partition data easily to parallelise the processing of records, while preserving order for records that are causally related. A consumer group can be used to disperse the partitions evenly among a population of consumers within a group — a load-balancer of sorts. It deals with the scaling of consumers as well as failures within the consumer group — redistributing the load among the surviving members of the group. In the diagram above, this is broadly labelled as ‘arbitration logic’. Mimicking this functionality requires you to essentially build a group membership service from the ground up, as well as a failure detector. If using Java, you could defer to a library — such as JGroups. Alternatively, group membership may be implemented atop Consul or Apache ZooKeeper if you need to interoperate with other languages. Or if you really want to be austere, you could lean on the database to help arbitrate group membership — ordinarily via some application-level leasing protocol. Where the arbitration logic resides is a separate question; the arbitration logic may be packaged as a standalone process, or it may be embedded into the consumer’s process space. Taking the latter leaves you with fewer ‘moving parts’, but results in a more complex consumer implementation and loss of reusability if the consumer ecosystem is implemented in multiple programming languages. At any rate, you are accumulating complexity — the very thing you’ve set out to avoid.
Next: housekeeping. Storage is cheap, but not free. Neither is I/O, especially when dealing with very large B-tree indexes that have bloated and fragmented over time. Implementing basic time-based purging is not difficult in itself, but it does require somewhere to host the scavenger logic — typically in a dedicated process (like a CRON job). Alternatively, you might host the scavenger in a producer or consumer process, which may require some coordination logic and, once again, loss of reusability in a polyglot ecosystem. Storage tiering takes complexity up a notch. Finally, you might need to implement compaction at some point — deleting event records that have been superseded by more recent events, thereby cutting down on consumer-side processing. Now, you’re performing complex and resource-consuming queries, balancing functionality with maintainability and performance.
Another, oft-overlooked feature of an event streaming platform is access control. Kafka offers fine-grained control over all actors (consumers, producers, administrators) in the system, the types of operations (read, write, create, delete, modify, etc.) they are permitted to invoke and the resources (topics, consumer groups, configuration) that may be manipulated. In other words, we can control exactly who gets access to what. In a tiny system where two processes communicate over a shared medium, security may be overlooked. However, as our system grows, information security becomes imperative. Most databases offer access control; however, its granularity is limited to table level. Where a table hosts logically separate record sets, this may not be sufficient — forcing you to split your records across tables and assign permissions accordingly. Were you hoping to sidestep a broker? Sorry, old chap.
Building these capabilities (and numerous others that I’ve not mentioned) on top of a database — while possible, is a non-trivial undertaking. Implementing this from first principles is both time-consuming and error-prone, and requires a “particular set of skills”.
From a non-functional standpoint, Kafka is optimised for high levels of throughput, both on the producer side (publishing lots of records per unit of time) and on the consumer side (processing lots of records in parallel where possible). Databases can’t touch this.
General-purpose databases — both relational and the No/NewSQL kind — are generally geared towards a broad spectrum of storage and retrieval patterns. Naturally, performance is a compromise. Kafka can comfortably handle moving millions of records per second on commodity and Cloud hardware, with latencies that vary between 10s and 100s of milliseconds. I’ve explained how it achieves this in the mildly popular Why Kafka is so Fast article. I’ll summarise here, for the reader’s convenience.
Without dwelling on the definition of ‘fast’, Kafka achieves its trademark performance characteristics due to certain deliberate design decisions, such as using an append-only log (avoiding random I/O), batching reads and writes, batch compression, unflushed buffered writes (avoiding fsync), zero-copy (I/O that does involve the CPU and minimises mode switching), bypassing garbage collection, and several others. Conversely, Kafka does not offer efficient ways of locating and retrieving records based on their contents — something that databases do reasonably efficiently. (This is why Kafka cannot be regarded as a database; not without twisting the basic definition.) But as a distributed, append-only log, Kafka is unrivalled.
Achieving similar throughput and latency figures in a database will likely require a combination of specialised hardware and highly focused performance tuning — a niche skill in itself. Depending on the chosen database, this may not be practically achievable. Designing and building data-intensive, distributed systems in a performance-sensitive environment also assumes an exceptional level of engineering competence across several disciplines.
Take one example — offset commit management. Kafka’s speed comes from efficiency. Unlike traditional message brokers that remove messages at the point of consumption (incurring the penalty of random I/O), Kafka doesn’t purge messages after they are consumed — instead, it independently tracks offsets for each consumer group by publishing special ‘offset’ records on an internal topic. (In effect, applying itself recursively.) Consumers in Kafka are ‘cheap’, insofar as they don’t mutate the log files. This means that a large number of consumers may concurrently read from the same topic without overwhelming the cluster. There is still some cost in adding a consumer, but it is mostly sequential reads with a low rate of sequential writes. So it’s fairly normal to see a single Kafka topic being shared across a diverse consumer ecosystem.
Emulating consumer groups on top of a database is certainly possible, but it’s not exactly trivial, nor performant — updating a consumer’s offset requires database I/O, which isn’t cheap. Alternatively, you might mimic consumer groups by physically or logically duplicating the records for each set of consumers — much like the fan-out strategy employed by RabbitMQ and similar products — then deleting the records immediately post-consumption. Again, database I/O is unavoidable; worse, you’re now amplifying writes. You might even embark on the optimisation route: employ a different database for tracking offsets, or even a disk-backed, in-memory cache — such as Redis, Hazelcast or Apache Ignite. I/O becomes cheaper at the expense of complexity.
In stating the above, perhaps you have a pint-sized system, your messaging requirements are very rudimentary and your performance and availability needs are modest. In which case, the points above are less likely to convince you; a database-backed solution may appear more enticing and conceptually simpler. The mere thought of dispensing with a broker may be alluring. You may have built similar database-backed solutions in the past and, understandably, you feel confident that you can adapt the existing code with minimal effort.
That’s fair enough. However, I would urge you to consider your future needs as well as your present. You need to be certain that whatever solution you deploy today can be comfortably maintained by you and your colleagues (the emphasis on the latter) in years to come. The system needs to cope with the future load, or at the very least, offer an avenue for growth. I like to think that in some parallel universe, we’re all renowned experts on distributed and fault-tolerant systems, and ultrafast, infinitely scalable databases are everywhere. The reality is more sobering. The advantage of using an off-the-shelf event-streaming platform like Kafka is that you capitalise on the Herculean engineering effort that has gone into its construction — the platform has been around for around a decade now, originally incubated by LinkedIn before going open-source in 2011. This translates into a myriad of essential features, stability, performance, and the backing of a vast and motivated engineering community that assures the continuity of the product.
How does all this relate to the Top Gear episode, you might ask? The protagonists were tasked with achieving an unrealistic goal with insufficient resources. Done in the name of entertainment and brilliantly so — a memorable laugh at their expense for your ultimate viewing pleasure. Equally, attempting to emulate a moderately functional and performant event streaming platform on top of a shared database is both futile and mildly satirical. If anything, it’ll be memorable.
Is there no room for database-backed solutions in the handling of event-centric data? Sure, there is. Databases can coexist harmoniously alongside event streaming platforms in an event-driven architecture. This was the basis of another short thesis — The Design of an Event Store. There, I suggest that most functions expected of an event store — entity state snapshots, secondary indexing, entity mutation history, windowing and aggregation, stream joins, among others — can only be implemented using a database. I also argue that there is no one-size-fits-all event store; any non-trivial event store is almost certainly a bespoke implementation, backed by one or more off-the-shelf databases. By and large, databases are supremely useful at organising data for efficient retrieval, so long as you’re not using them as a (near-)real-time distribution platform.
Source: https://towardsdatascience.com/